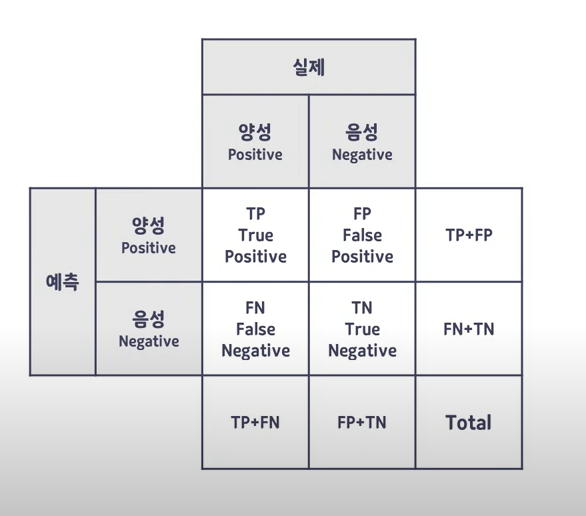
TP : 실제로 양성인 것을 양성이라고 맞게 예측
TN : 실제로 음성인 것을 음성이라고 맞게 예측
FN : 실제로 양성인 것을 음성이라고 틀리게 예측
FP : 실제는 음석인 것을 양성이라고 틀리게 예측
정분류율( Accuracy)
계산식 : (TP + TN) / (TP + TN+ FN+FP)
전체 데이터 중에 모두 잘 맞게 분류한 비율
오분류율( Error Rate)
계산식 : ( FP + FN ) / (TP + TN+ FN+FP)
전체 데이터 중에 모두 틀리게 분류한 비율
민감도(Sensitivity) = 재현율 (Recall)
계산식 : TP / (TP+FN)
실제 양성인 데이터를 판별하여 정말로 맞게 양성으로 분류한 비율
특이도(Specificity) = 진음성률(True Negative Rate, TNR)
실제 음성 중에서 모델이 음성으로 올바르게 예측한 비율
Specificity = TN / (TN + FP)
정확도(Precision)
모델이 양성으로 판단 한 것 중 실제 양성 비율
Accuracy = (TP) / (TP + FP)
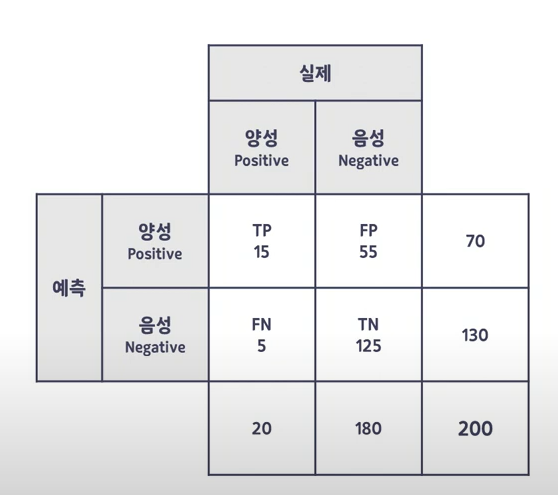
정분류율 (15+125) / 200
오분류율 (55+5) / 200
민감도 15 / 20
특이도 125 / 180
정확도15 / 70

F1-score는 이진 분류 모델의 성능을 평가하는 데 널리 사용되는 지표입니다.
정밀도(Precision)와 재현율(Recall)의 조화평균으로 계산되며, 모델의 전반적인 성능을 나타내는 단일 숫자로 표현합니다. 예시를 통해 F1-score에 대해 자세히 설명하고, 왜 모델 평가에 좋은 지표인지 알아보겠습니다.
예시:
한 병원에서 당뇨병 진단 모델을 개발했습니다. 이 모델은 환자의 데이터를 분석하여 당뇨병 여부를 예측합니다. 총 100명의 환자 중 실제로 당뇨병인 환자는 20명이고, 나머지 80명은 당뇨병이 아닙니다. 모델의 예측 결과는 다음과 같습니다:
모델이 당뇨병이라고 예측한 환자: 25명 (TP + FP)
그 중 실제 당뇨병인 환자: 15명 (TP)
실제 당뇨병이 아닌 환자: 10명 (FP)
모델이 당뇨병이 아니라고 예측한 환자: 75명 (TN + FN)
그 중 실제 당뇨병이 아닌 환자: 70명 (TN)
실제 당뇨병인 환자: 5명 (FN)
정밀도(Precision) = TP / (TP + FP) = 15 / (15 + 10) = 0.6 (60%)
재현율(Recall) = TP / (TP + FN) = 15 / (15 + 5) = 0.75 (75%)
F1-score = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.6 * 0.75) / (0.6 + 0.75) = 0.9 / 1.35 = 0.6667 (66.67%)
이 예시에서 F1-score는 0.6667로, 당뇨병 진단 모델의 전반적인 성능을 나타냅니다.
F1-score가 모델 평가에 좋은 지표인 이유:
정밀도와 재현율의 균형 고려: F1-score는 정밀도와 재현율의 조화평균이므로, 두 지표 간의 균형을 고려합니다. 어느 한 쪽에 치우치지 않고 모델의 전반적인 성능을 평가할 수 있습니다.
불균형한 데이터셋에서의 유용성: 실제 데이터셋은 종종 클래스 간 불균형이 존재합니다. 예를 들어, 당뇨병 환자의 수가 비당뇨병 환자에 비해 현저히 적을 수 있습니다. 이런 상황에서 정확도(Accuracy)만으로는 모델의 성능을 제대로 평가하기 어려울 수 있습니다. F1-score는 이러한 불균형한 데이터셋에서도 모델의 실제 성능을 잘 반영할 수 있습니다.
단일 지표로 모델 비교 용이: F1-score는 모델의 성능을 단일 숫자로 나타내므로, 서로 다른 모델을 쉽게 비교할 수 있습니다. 이는 최적의 모델을 선택하는 데 도움이 됩니다.
다양한 분야에서 널리 사용: F1-score는 이진 분류 문제뿐만 아니라 다중 클래스 분류, 객체 검출, 정보 검색 등 다양한 분야에서 널리 사용되는 지표입니다. 이는 F1-score가 다양한 상황에서 모델의 성능을 효과적으로 평가할 수 있음을 보여줍니다.
F1-score는 정밀도와 재현율의 조화를 고려하여 모델의 전반적인 성능을 평가하는 데 매우 유용한 지표입니다. 특히 불균형한 데이터셋을 다룰 때 F1-score의 중요성이 더욱 부각됩니다. 하지만 모델 평가 시에는 F1-score 외에도 다른 지표와 함께 종합적으로 고려하는 것이 좋습니다.
'DeepLearning' 카테고리의 다른 글
| CVAT 오픈소스 구축 방법 정확하게 알려드립니다 feat . Docker, Git 세팅 (18) | 2024.04.25 |
|---|---|
| "유니티의 AI 플랫폼 출시: 게임 개발과 3D 콘텐츠 제작을 혁신하다" (0) | 2023.09.07 |
| 데이터 어노테이션(Data Annotation) :데이터 라벨링 6가지에 대한 설명 (0) | 2023.05.17 |
| [책]혼자 공부하는 머신러닝 / 딥러닝 _정말 혼자 공부하는 AI_구글 코랩 사용법 (0) | 2023.02.28 |
| 온오프믹스 모임문화 플랫폼을 통해 참여하게 된 AI 개발 스터디 모임 (0) | 2023.02.18 |
| How to create a Google Chrome extension program with ChatGPT(ChatGPT로 구글 크롬 확장 프로그램 만드는 방법) (0) | 2023.02.03 |



