
노트북
코랩은 구글이 대화식 프로그램이 환경이 주피터를 커스터마이징한 것 입니다.
파이썬 지원으로 시작한 주피터 프로젝트는 최근에는 다른 언어도 지원합니다.
주피터 프로젝트의 대표 제품이 바로 노트북입니다.
코랩 노트북은 구글 크라우드의 가성 서버를 사용합니다.
화면 오른쪽 산단에 있는 RAM ,디스크 아이콘에 마우스를 올리면 상세 정보를 알 수 있습니다.
코드를 실행하기 전이나 연결이 끊어진 상태에서는 아이콘 대신에 연결 버튼이 활성화 됩니다.


이 노트북은 구글 클라우드의 컴퓨터 엔진에 연결되어 있습니다. 이서버의 메모리는 약 12기가이고 디스크 공간은 100기가입니다. 개인 컴퓨터의 사양에 구애 받지 않고 머신러닝/ 딥러닝을 진행할 수 있습니다.

코드 셀을 실행 시킬려면 Ctrl + Enter를 누르면 실행이 됩니다.
노트북은 자동으로 구글 드라이 의 [내드라이브] -[Colab Notebooks] 폴더 아래에 저장됩니다.
웹 브라우저에서 구글 드라이브로 접속해서 확인 가능합니다.
//
생선 분류 문제
마켓에서 팔기 시작한 생선은 '도미' , '곤들매기', '농어' , 등등 입니다.
이 생선들은 물류 센터에 많이 준비되어 있습니다. 이 생선들을 프로그램으로 분류한다고 가정하면 어떻게 프로그램을 만들 수 있을까
생선의 특징이 중요합니다.
생선길이가 30cm 이상이면 도미라고 알려줬다고 생각해봅시다.
파이썬으로 프로그램을 만들었습니다.
if fish_length >= 30:
print("도미")
하지만 무조건 도미라고 말할 수 없습니다.
또 도미의 크기가 모두 같을 리도 없겠죠
이문제를 어떻게 머신러닝으로 해결할 수 있을까
보통 프로그램을 누가 정해준 기준대로 일을 합니다.
머신러닝은 누구도 알려주지 않는 기준을 찾아서 일을 합니다.
기준을 알아서 찾고 이 기준으로 정확하게 해당 물고기가 도미인지 아닌지 구분할 수 있죠
그럼 그 기준이 되는 데이터를 찾아야합니다.
여러개의 도미 데이터를 많이 준비해야합니다.
새노트를 만들어 줍니다. [BreamAndSmelt] ->[도미와빙어]

https://gist.github.com/rickiepark/b37d04a95a42ef6757e4a99214d61697
도미의 길이, 무게 데이터
도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
도미 데이터인 파이썬 리스트를 입력해야하는데 위의 깃허브에서 복사해서 입력하자!
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]

두 특성을 숫자로 보는 것 보다 그래포로 표현하면 데이터를 잘 이해할 수 있고 앞으로 할 작업에 대한 힌트를 얻을 수 도 있습니다. 길이를 x축으로 하고 무게를 y축으로 정하겠습니다. 그다음 각 도미를 이 그래프에 점으로 표시해 보조 이런 그래프를 산점도라고 부릅니다.
파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지는 맷플롯립[matplotlib]입니다. 이패키지를 임포트ㅏ고 산점도를 그리는 scatter() 함수를 사용해보겠습니다.
import matplotlib.pyplot as plt
plt.scatter(bream_length , bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()

이렇게 나옵니다.
빙어 데이터도 동일하게 입력하여 진행해 줍니다.

그래프를 보면 빙어는 길이와 무게가 비례는 하지만 크게 영향을 많이 받는 편이 아니라는 점을 확인 할 수 있습니다.
두 데이터를 스스로 구분하기 위한 첫 번째 머신러닝 프로그램을 만들어 보겠습니다.
K-최근접 이웃 ( K- Nearest Neighbors) 알고리즘을 사용해 도미와 빙어 데이터를 구분해 보겠습니다.
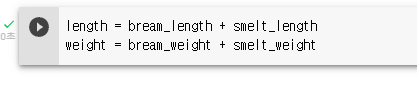
두 리스트를 하나로 합치고
머신러닝 패키지 사이킷 런 을 사용할 것 입니다.
scikit-learn
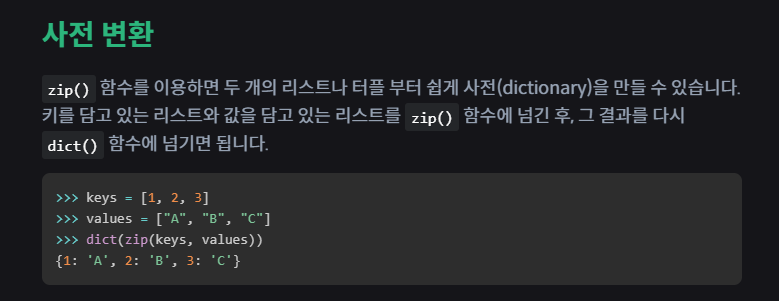
* 이 패키지를 사용하려면 다음처럼 각 특성의 리스트를 세로 방향으로 늘어뜨린 2차원 리스트를 만들어야 합니다.
파이썬은 zip() 함수와 리스트 내포 구문을 사용하는 것입니다.

[[25.4, 242.0],
[26.3, 290.0],
[26.5, 340.0],
[29.0, 363.0],
[29.0, 430.0],
[29.7, 450.0],
[29.7, 500.0],
[30.0, 390.0],
[30.0, 450.0],
[30.7, 500.0],
[31.0, 475.0],
[31.0, 500.0],
[31.5, 500.0],
[32.0, 340.0],
[32.0, 600.0],
[32.0, 600.0],
[33.0, 700.0],
[33.0, 700.0],
[33.5, 610.0],
[33.5, 650.0],
[34.0, 575.0],
[34.0, 685.0],
[34.5, 620.0],
[35.0, 680.0],
[35.0, 700.0],
[35.0, 725.0],
[35.0, 720.0],
[36.0, 714.0],
[36.0, 850.0],
[37.0, 1000.0],
[38.5, 920.0],
[38.5, 955.0],
[39.5, 925.0],
[41.0, 975.0],
[41.0, 950.0],
[9.8, 6.7],
[10.5, 7.5],
[10.6, 7.0],
[11.0, 9.7],
[11.2, 9.8],
[11.3, 8.7],
[11.8, 10.0],
[11.8, 9.9],
[12.0, 9.8],
[12.2, 12.2],
[12.4, 13.4],
[13.0, 12.2],
[14.3, 19.7],
[15.0, 19.9]]마지막으로 준비할 데이터는 정답 데이터 입니다.
왜 필요할까 ?
도미와 빙어를 구분하는 규칙을 찾기를 원하면 적어도 어떤 생선이 도미인지 빙어인지 알려주어야합니다.
곱셈 연산자를 사용하면 파이썬 리스트를 간단하게 반복시킬 수 있습니다.

이제 사리킷 런 페키지에서 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트합니다.

kn 객체에 fish_data와 fIsh_target을 전달하여 도미를 찾기 위한 기준을 학습시킵니다.
이런 과정을 머신러닝에서 훈련이라고 부릅니다.

fit()메서드는 주어진 데이터로 알고리즘을 훈련시킨 뒤 훈련합니다.
이객체 또는 모델 kn이 얼마자 잘 훈련되었는지 평가해 보겠습니다.
사이킷런에서 모델을 평가하는 메서드는 score() 메서드입니다. 0~1의 값이 나옵니다.

이 값을 정확도(accuracy)라고 부릅니다.
오늘은 여기까지
'DeepLearning' 카테고리의 다른 글
| F1-Score에 대하여 [ 정분류율, 오분류율 , 민감도, 재현율, 특이도, 정확도, F1-Score] (0) | 2024.04.18 |
|---|---|
| "유니티의 AI 플랫폼 출시: 게임 개발과 3D 콘텐츠 제작을 혁신하다" (0) | 2023.09.07 |
| 데이터 어노테이션(Data Annotation) :데이터 라벨링 6가지에 대한 설명 (0) | 2023.05.17 |
| 온오프믹스 모임문화 플랫폼을 통해 참여하게 된 AI 개발 스터디 모임 (0) | 2023.02.18 |
| How to create a Google Chrome extension program with ChatGPT(ChatGPT로 구글 크롬 확장 프로그램 만드는 방법) (0) | 2023.02.03 |
| Chatbots: The Future of Customer Service (0) | 2023.02.02 |


